
Why I Built an AI Framework in PHP in 2026, and What I Learned About Multi-Provider AI Gateways in the Process
Merge Conflict #002 - Three providers, three different opinions on what a response looks like

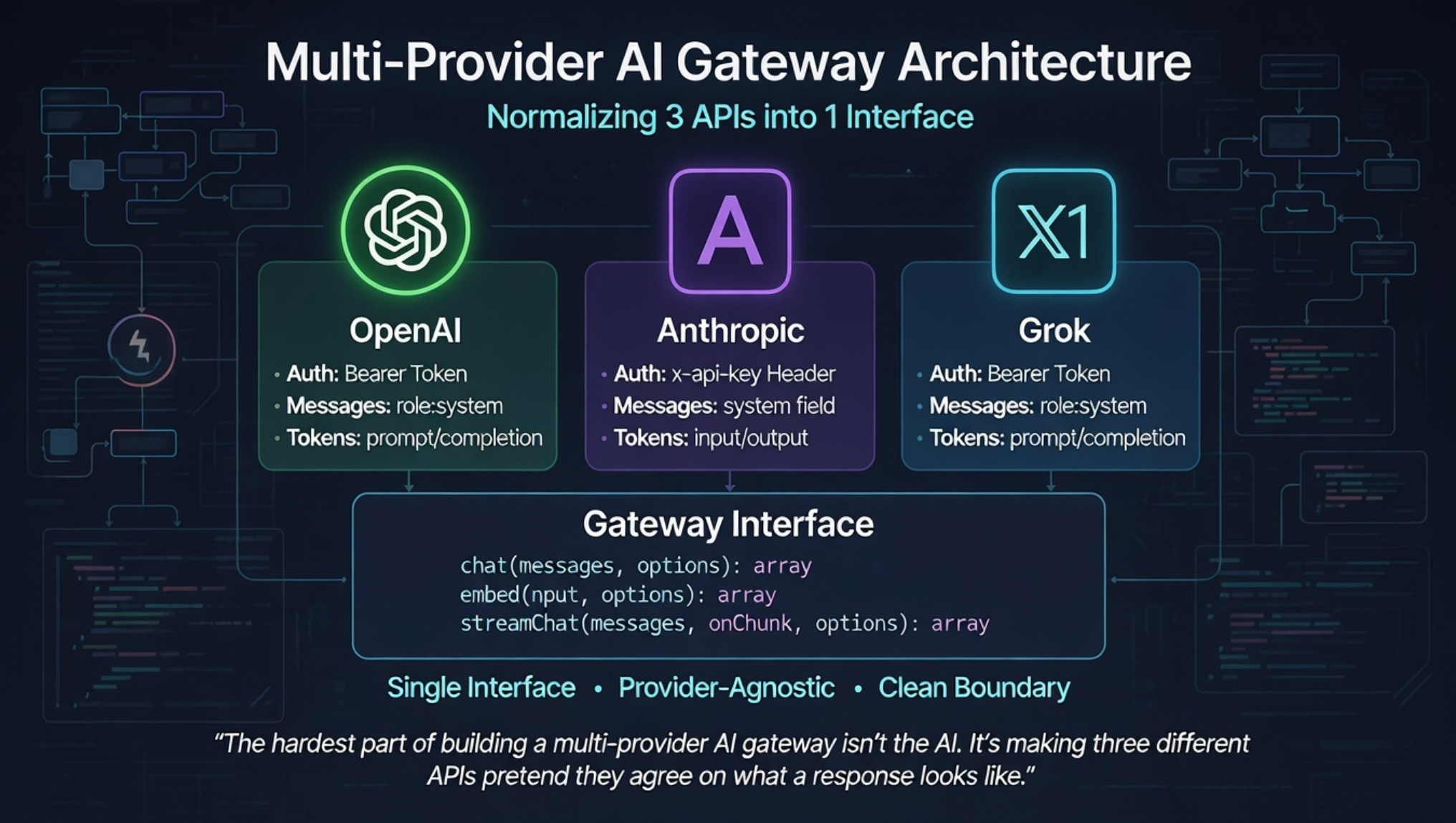
The hardest part of building a multi-provider AI gateway isn’t the AI. It’s making three different APIs pretend they agree on what a response looks like.
I’m George Violaris, CTO at Hatchworks VC. I build AI products and ship them. Over the past few months I’ve been building Smallwork, a full-stack PHP AI framework with a multi-provider gateway that talks to OpenAI, Anthropic, and Grok through a single interface. Zero external dependencies. PHP 8.2+.
Why PHP? Because that’s what runs some critical parts of our stack. Most of the web runs on PHP, and when you need AI in a PHP application, your options are: bolt on a Python microservice, pay for a third-party gateway, or build the abstraction yourself. I built it myself. But the interesting part isn’t the language. The interesting part is what I learned about normalizing three provider APIs into one clean interface. Streaming formats that disagree. Auth schemes that don’t match. Response shapes that look similar until they don’t.
Provider normalization sounds simple on a whiteboard. In practice, it’s where your architecture lives or dies. Here’s what it looks like from the inside.

The Reality: What Providers Actually Differ On
If you’ve only ever used one AI provider, you probably think switching to another is a weekend project. Swap the base URL, update the API key, done. I thought that too. Then I actually built a gateway that talks to OpenAI, Anthropic, and Grok, and I can tell you: the differences start on request number one and they never stop.
Let’s start with something as basic as authentication. OpenAI and Grok both use standard Bearer token auth — `Authorization: Bearer {key}` in the header. Anthropic doesn’t. Anthropic uses a custom `x-api-key` header, and it also requires you to send an `anthropic-version` header (currently `2023-06-01`) on every single request. Miss that version header and you get a wall of errors with no obvious explanation. Two out of three providers do it the same way, and the third does something completely different. That’s the pattern for everything that follows.
Message formatting is where it gets more interesting. OpenAI and Grok treat system messages like any other message — they sit in the `messages` array with `role: ‘system’`. Anthropic extracts the system prompt into its own top-level `system` field. Which means your gateway can’t just forward messages through. It has to inspect them, pull out the system message, restructure the payload, and build a different request body depending on who it’s talking to. In Smallwork, the `AnthropicProvider` loops through the messages array, filters out any system message, and moves it to a separate field on the request body. It’s not complicated code, but it’s code that has to exist, and if you forget it, your system prompt silently disappears.
Then there’s token reporting. You make a request, you get back usage data. OpenAI and Grok call them `prompt_tokens` and `completion_tokens`. Anthropic calls the same numbers `input_tokens` and `output_tokens`. Same concept, different keys. If you’re tracking costs, logging usage, or enforcing budgets across providers, you need a normalization layer just for this. In Smallwork, the Anthropic provider maps `input_tokens` to `prompt_tokens` and `output_tokens` to `completion_tokens` in the response so the rest of the application never has to care which provider generated the data.
Now for the real fun: capability gaps. Not every provider does the same things. Call `embed()` on the Anthropic provider in Smallwork and you get a `RuntimeException` — “Anthropic does not support embeddings. Use OpenAI or another provider.” That’s it. No fallback, no partial support, just a hard stop. Meanwhile, Grok ships its own embedding model (`grok-embed`) using the same request/response structure as OpenAI. Your gateway needs to know what each provider can and can’t do, and it needs to fail clearly when someone asks for something that isn’t available.
Here’s what it looks like side by side:
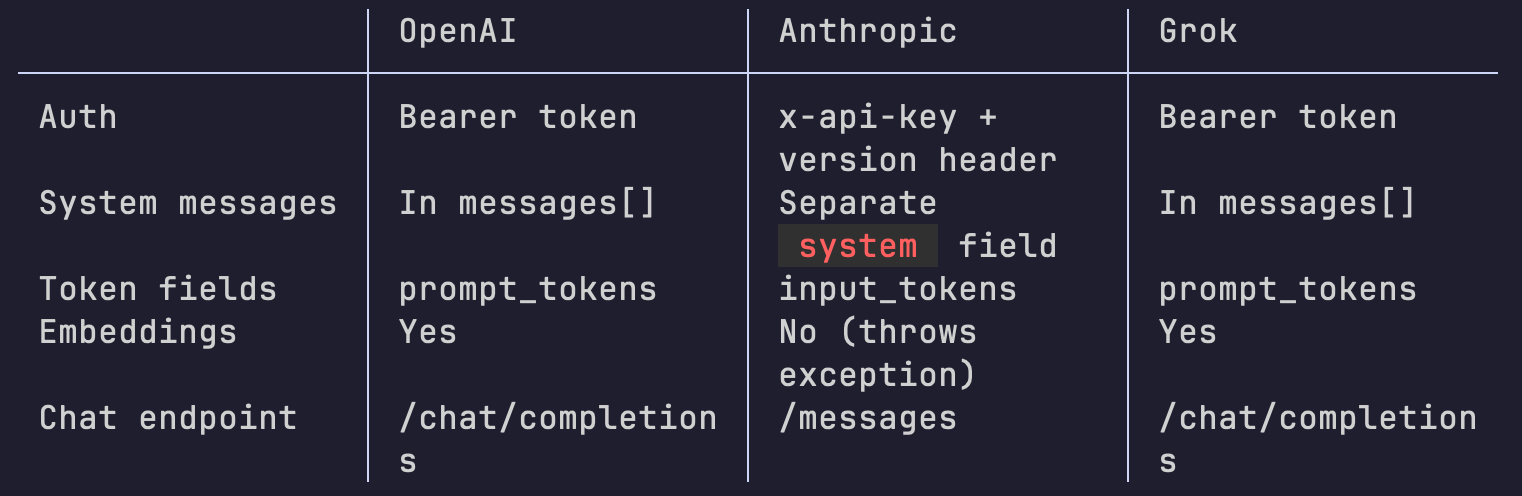
That table covers five dimensions and three providers. That’s fifteen potential mismatches, and I haven’t even touched streaming, where the SSE chunk structures differ between providers, or the fact that each provider supports a different subset of tuning parameters (`frequency_penalty` and `presence_penalty` exist on OpenAI but not on Grok’s implementation).
These aren’t edge cases you might hit someday. They’re the first things you hit when you try to swap providers. And they compound. Every new feature you add (tool use, structured output, image inputs) multiplies the surface area of divergence. This is why a multi-provider gateway isn’t a nice-to-have abstraction. It’s load-bearing architecture.
How the Gateway Pattern Solves It
So you’ve got three providers that disagree on everything. The question is where you put the translation logic. You can scatter it across your application — `if anthropic do this, else do that` — and watch your codebase rot in real time. Or you can push all of it to the edge, behind a single interface, and never think about it again in your application code.
That’s the gateway pattern. In Smallwork, it starts with a three-method contract:
interface ProviderInterface
{
public function chat(array $messages, array $options = []): array;
public function embed(string|array $input, array $options = []): array;
public function streamChat(array $messages, callable $onChunk, array $options = []): array;
}That’s the entire surface area. Every provider — OpenAI, Anthropic, Grok — implements this interface. Three methods. Same signatures. Same return shapes. If you can implement these three methods, you have a working provider.
The `Gateway` class itself is a router. It holds a registry of providers, each registered under a name. When you call `$gateway->chat($messages, ‘anthropic’)`, it resolves the provider by name and delegates. You set a default provider in the constructor so most calls don’t need to specify one at all. Want to switch from OpenAI to Grok for a single request? Pass the name. Want to switch your entire application’s default? Change one string. Your business logic stays untouched.
What matters is where normalization happens. Each provider adapter handles its own mess internally. The `AnthropicProvider` knows that system messages need to be extracted from the messages array and moved to a top-level `system` field. It knows that `input_tokens` needs to become `prompt_tokens` in the response. It knows about the `x-api-key` header and the version requirement. All of that lives inside the Anthropic adapter, and it never leaks out. What comes back to your application is always the same shape: `[’content’ => string, ‘usage’ => [...], ‘model’ => string]`. Every time. Regardless of who generated it.
This is the thing that separates a gateway from a wrapper: normalization work scales per provider, not per feature. When I added streaming support, I didn’t touch three different parts of the application. I added `streamChat` to each provider adapter, handled the SSE format differences inside each one, and the gateway got a new method that delegates the same way `chat` does. When I eventually add tool use, same thing. One implementation per provider, behind the same interface.
Adding a new provider is a contained task. Implement `ProviderInterface`, handle whatever quirks that provider brings in your adapter, register it with the gateway. Your controllers, your RAG pipelines, none of them change. They talk to the gateway. The gateway talks to providers. The boundary is clean.
This isn’t theoretical. I’ve swapped default providers in Smallwork applications by changing a config value. No refactoring, no “find and replace across 40 files,” no subtle bugs from a missed token field mapping. The gateway absorbs the complexity so the rest of the system doesn’t have to.
What the AI Middleware Layer Enables
Here’s where it gets interesting. Once the gateway gives you a single, provider-agnostic interface, you can start treating AI as just another tool in your request pipeline. Not a special service you call from deep inside your business logic. Middleware. The same pattern you already use for auth, CORS, and rate limiting.
In Smallwork, AI middleware sits in the HTTP pipeline alongside everything else. A request comes in, passes through your standard middleware stack, and somewhere in that stack, between authentication and your controller, AI does its thing. The request keeps moving. Your controller doesn’t know or care that an AI provider was involved.
Take content moderation. Before a user’s input ever reaches your controller, a moderation middleware intercepts the request, sends the content through the gateway for classification, and either lets it pass or returns a 422 right there. The controller never sees unsafe content. It doesn’t need moderation logic. It doesn’t need to know which AI provider made the call. That decision was made three layers up in the pipeline.
Or intent classification. A middleware reads the user’s message, asks the gateway to classify it (question, command, feedback, complaint) and tags the request with that intent before passing it along. By the time your controller picks up the request, the intent is already there as a request attribute. You route based on it, you log it, you use it however you want. But the classification happened in the middleware, not in your business logic.
Same idea for auto-summarization. If a user sends a wall of text that exceeds a character threshold, a middleware condenses it through the gateway and attaches the summary to the request. Your controller gets both the original and the summary without ever asking for it.
The pattern here matters more than the individual examples. These aren’t AI infrastructure concerns. They’re web framework concerns. The only difference between an auth middleware and a content moderation middleware is that one checks a token and the other checks a prompt response. They both sit in the same pipeline, follow the same contract, and either pass the request forward or stop it cold.
That’s what the gateway unlocks. Once you normalize providers, AI stops being a special architectural category and becomes a dependency you inject, like a database connection or a cache layer. You compose it into your application the same way you compose everything else. No ceremony. No separate “AI service layer.” Just middleware with an AI provider behind it.
From the Reading List
I keep coming back to Gregor Hohpe’s Enterprise Integration Patterns. It’s from 2003 and it’s about messaging systems, not AI. But the core idea — that you solve integration problems by normalizing message formats at the boundary, not by teaching every consumer to understand every producer — is exactly what a multi-provider gateway does. Different era, same pattern. I picked it up again while designing Smallwork’s provider layer, and it’s the reason the gateway looks the way it does. If you build anything that talks to more than one external service, this book will pay for itself in the first chapter.
Wrapping Up
Provider normalization isn’t a PHP problem. It’s not a Python problem either. It’s an engineering problem. The patterns here — adapter, gateway, normalized interface — work in any language, with any set of providers. Smallwork happens to do it in PHP with zero external dependencies, but that’s an implementation detail. The point is that a well-designed abstraction makes multi-provider AI tractable. Without one, you’re scattering translation logic across your entire codebase and hoping nobody ships a breaking change on a Friday. With one, you add a provider by implementing three methods and registering it. Your application never notices.
If you take one thing from this issue, make it this: don’t abstract AI because it’s elegant. Abstract it because the providers will keep diverging, your application will keep growing, and the translation surface between them will compound until it’s either contained in one place or smeared across everything you build. The language you write it in is incidental. The architecture isn’t.
That’s issue two. Here’s what’s coming:
Issue #003: How I built an AI-agent-first frontend framework in 1,200 lines of TypeScript, and why agents need to understand UI, not just scrape it.
If something in here resonated, forward it to someone who ships. If you disagree, reply — I read everything.
See you next time.
— George